基于Python、scrapy爬取软考在线题库
前言
前段时间,报名个软件设计师考试,自然需要复习嘛,看到软考在线这个平台有历年来的题目以及答案,想法就是做一个题库小程序咯,随时随地可以打开复习。很多人问,这不出现很多类似的小程序了?是的,但是他们的要不需要付费,要不一大堆广告,这激发我自己做一个小程序的想法。
实战爬取题库
随便找一科(这里就拿软件设计师上午题吧)
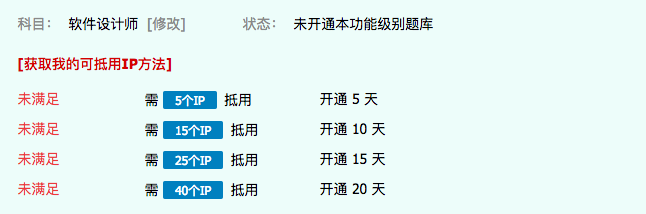
进入某一道题目点击查看答案,会出现要开通权限才行,正好有一个免费开通的方式,通过IP数量兑换(这么说,这种营销模式很ok,达到宣传效果。但是咧,爱折腾的博主就是爱折腾,怎么能够说我要找几十个人帮我点击一下链接吧。)
敲重点啦,你用手机浏览器打开刚刚官方给链接,切换飞行模式就可以实现获得IP的方法。博主吐槽的是浏览器竟然不做缓存处理,随便就可以得到IP。

接着分析ajax中获取答案
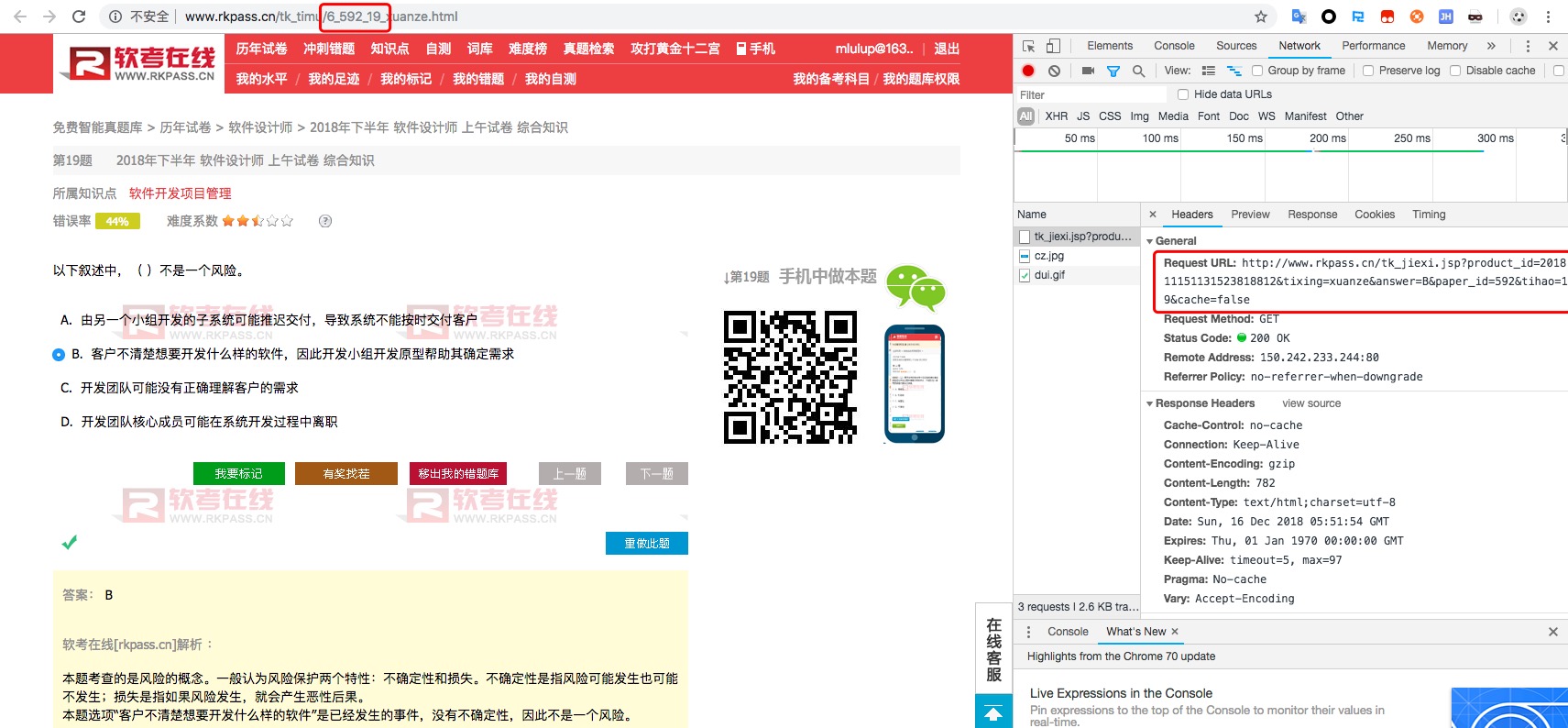
首先试下复制红色框中url链接直接浏览器打开,OK,发现能够打开,说明没有做任何接口限制,所以可以推断前面通过IP数量兑换权限天数的是一个形同虚设的东西。
接着分析url中参数的意思,product_id、tixing、answer、paper_id、tihao、cache这几个参数。猜测product_id应该唯一的东西,请求接口应该只需要这个参数就ok吧。实践是检验真理的唯一标准。把链接改成如下,只有product_id传入参数尝试,能打开并且可以显示出需要的答案。鉴定猜想没有问题。
http://www.rkpass.cn/tk_jiexi.jsp?product_id=201811151131523818812&tixing=xuanze&answer=&paper_id=&tihao=&cache=如何获取product_id?既然是唯一性的东西,这值肯定会后端回传过来,如果后端没有分离那肯定渲染在html中,若是前后端完全分离那肯定包含在请求题目的接口中。很巧,不是前后端完全分离的项目,那肯定是在html中咯,常规操作鼠标右键->显示网页源代码->Ctrl+F搜索就完事。果不其然,出现想要的的值。

上面两步是分析的过程,下午题也是差不多啦。剩下的就是爬下来并且存入数据库中就OK。
这是博主自己用Python3+scrapy爬取实现代码Python基于Scrapy爬取www.rkpass.cn题目,赶紧star吧,支持下博主。

谢谢
挺好的学习了
作为同行我提醒你一句,这篇文章可能是你犯罪的铁证,建议你马上删除。 你可以看看百度和大众点评的案例,酷米客和车来了的案例,连工程师都被抓了,这种有商业价值的信息,在没有得到授权的情况下被你抓取了,你还写这篇文章,你怕别人不知道啊。
1