基于Python、scrapy爬取软考在线题库
前言
前段时间,报名个软件设计师考试,自然需要复习嘛,看到软考在线这个平台有历年来的题目以及答案,想法就是做一个题库小程序咯,随时随地可以打开复习。很多人问,这不出现很多类似的小程序了?是的,但是他们的要不需要付费,要不一大堆广告,这激发我自己做一个小程序的想法。
前段时间,报名个软件设计师考试,自然需要复习嘛,看到软考在线这个平台有历年来的题目以及答案,想法就是做一个题库小程序咯,随时随地可以打开复习。很多人问,这不出现很多类似的小程序了?是的,但是他们的要不需要付费,要不一大堆广告,这激发我自己做一个小程序的想法。
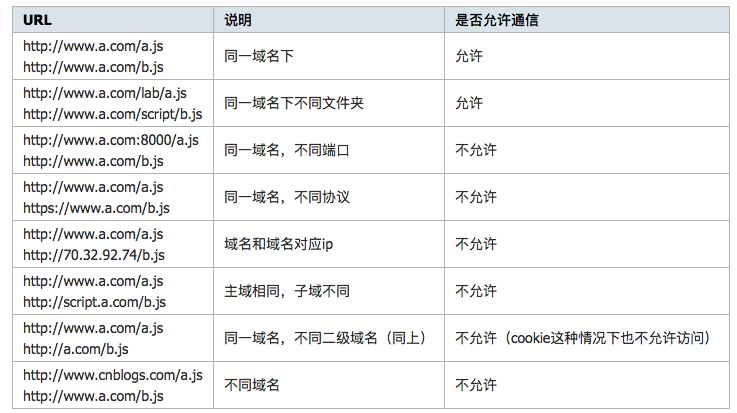
作为后端开发者,跨域问题并不是一个新鲜的事啦。
何为跨域? 浏览器的同源策略,同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。当对于不同源的文档或者脚本,浏览器会认为这是一个潜在恶意的文件,所以对其进行了拦截处理。
何为跨域? 简单来说,只有当协议,域名,端口号相同的时候才算是同一个域名,否则,均认为需要做跨域处理。下面看一张图(这张图已经说明的很详细啦)
对于图片下载,在scrapy框架中提供了专门下载的Pipeline,即ImagesPipeline这个是定义好的。但是对于我们来说,他的局限性很大,所以基本上我们需要重写一个Pipeline。怎么局限性?
内置的ImagesPipeline会默认读取Item的image_urls字段,并认为该字段是一个列表形式,它会遍历Item的image_urls字段,然后取出每个URL进行图片下载。而我们业务逻辑往往不是这样。
对于数据存储,通常情况下存入MySQL或者MongoDB两种数据存储。下面主要以MySQL为例子。再scrapy中有一个叫Pipeline(管道),scrapy对于爬数据的分工很明确,爬虫部分、数据定义部分、管道部分。管道部分主要实现对爬取的数据流进行后期存储或者清洗等等。
最近用Spring boot写Api接口,其中引入了FastJson这个阿里巴巴的一个包,用于序列化接口,刚入门Java写接口,看帖子都说这个不错,so 我也尝试了用这个。但是遇到一个很奇怪的问题,list中重复的部分直接用的是引用。当时一脸懵逼。